
Deep Learning study
Memorization Precedes Generation : Learning Unsupervised GANs with Memory Networks ( MemoryGAN ) 본문
Memorization Precedes Generation : Learning Unsupervised GANs with Memory Networks ( MemoryGAN )
illinaire 2019. 6. 15. 11:12오늘의 논문은 memoryGAN이다. 서울대학교 김건희 교수님연구실의 논문인데 정말 음.. 어렵고, 어려운만큼 잘 이해해보려고 노력했던 논문이다.
논문에 들어가기에 앞서, 읽기전에 이 글을 먼저 읽거나 해당 논문을 읽고 이것을 읽으면 많은 도움이 될 것이다.
GAN에관한 논문에는 항상 문제점을 가지고 시작한다. 여기서도 마찬가지로 GAN의 학습에있어서의 두가지 이슈를 가지고 시작하게 된다.
- GAN은 다수의 클래스나 데이터의 군집(cluster)를 임베딩하기위해서 continuous latent distribution만을 사용하기 때문에 서로다른 클래스들 사이의 구조적인 불연속을 다룰 수 없다.
- GAN의 discriminator는 과거에 generator가 생성해낸 sample들을 쉽게 잊어버린다.
이러한 문제점을 해결하기 위해서 소개한 것이 MemoryGAN 이다.
introduction
위의 두가지 이슈에 대해서 언급을 하였다. 조금 더 상세하게 다시 설명을 해보자.
첫 번째로 GAN은 unimodal continuous latent space( eg. normal distribution ) 을 사용하고, 그러므로 서로다른 클래스들사이의 구조적인 불연속을 다루는것에 실패하게 된다.
이렇게만 설명하면 사실 무슨말인지 잘 이해가 안 될수도있다. 그래서 친절하게 예시를 들어주었다.
어떠한 구조적인 상관이 없는 ,빌딩과 고양이를 continuous latent distribution에 임베딩했다고 해보자. 그렇다면 latent space에는 빌딩과 고양이를 포현하는 부분이 있을것이다. 하지만 두 클래스 사이의 latent code들은 고양이도아닌 빌딩도 아닌 어떤것을 표현하고 있는것일까? 당연히 이러한 latent code는 비현실적은 이미지를 생성할것이다.
조금 더 이해를 돕기위해서 아래의 그림을 보자.

이처럼 불연속적인 구조를 가지는 MNIST데이터에서 서로다른 클래스들 사이에는 위의 빨간 네모안의 숫자들처럼 비현실적인 이미지가 생성될 수밖에 없다. 예를들어서 사람의 얼굴이라는 하나의 클래스를 가정하면, 1번사람과 2번사람의 중간즈음에 있는 이미지를 생성한다면 그것은 제 3의 사람이 되겠지만, 이처럼 불연속적인 1,2,3,... 의 클래스를 가지는 숫자에서는 2와 3 사이의 숫자는 존재하지 않기때문에 비현실적인 이미지를 생성해내는 것이다.
두 번째로, GAN 학습 동안에 discriminator가 과거에 생성된 sample들을 잊어버리는(forgetting behavior) 것이다. 두가지의 네트워크(generator, discriminator)의 loss function이 서로 각자의 성능에만의존하기때문에, 이러한 forgetting behavior는 심각한 불안정을 가져오게된다.
이러한 문제들을 해결하기 위해서 간단한 memorization module 을 소개한다. 이 module은 GAN 학습에서의 불안정성을 완화시킬 수 있다.
- 구조적 불연속의 문제를 해결하기위해서 memory는 training sample들의 representation을 학습할 수 있다. 이것은 generator가 데이터의 분포에서 중요한 class 또는 cluster를 더 잘 이해하게 도와준다.
- generator가 생성해낸 sample들의 cluster를 기억하는것을 학습함으로써, memory network는 forgetting problem을 완화시킬 수 있다.
The MemoryGAN
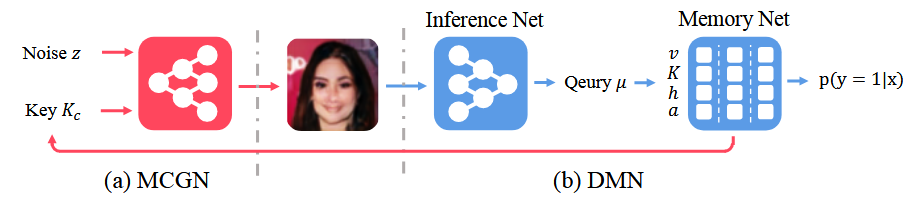
memoryGAN의 구조는 위와 같다. MCGN이라는 Memory Conditional Generative Network와 DMN이라는 Discriminative Memory Network로 구성된다. Generator와 Discriminator 둘 모두 Memory Net에 접근 가능하며, G는 noize z 와 memory의 key 값을 input으로 가지게 되며 DMN에서는 Inference Net을 거쳐나온 query로 Memory Net을 거쳐 real인지 fake인지를 판별하게 된다.
The discriminative Memory Network
DMN은 위에서 보다시피 Inference network와 Memory network로 구성되어져있다. inference net의 input은 datapoint 가 되고 ouput은 normalized 된 query vector q가 된다. 그러면 그 query q는 Memory module로 전달되어 x가 real 인지 fake 인지 판별하게 되는 것이다.
Memory network는 네가지의 구성요소로 이루어져있다.
이 구성요소들은 앞서 포스팅한 논문과 거의 비슷하므로 간략하게만 설명하고 넘어가자.
K : memory key의 matrix이다. Data sample이 Inference Net 을 을 거쳐서 나온 vector값이 되겠다.
v : memory value vector, 0과 1 의 값을 가지며 이것은 각각 fake 또는 real을 나타내게 된다.
a : 슬롯이 저장 된 순서를 나타내는 지표를 나타내는 vector이다.
h : 이전에 포스팅했던 memory net에서 추가된 요소이다. slot histogram을 나타내는데, 이것은 해당 슬롯의 중요도 정도로 이해하면 될 것같다.
앞서 말했듯이 이 memory net 구조는 life-long memory network(Kaiser et al., 2017)의 메커니즘을 빌려온 것이다. 하지만 여기서 사용하는 메모리 구조에는 새로운 몇가지의 특징들이 있다고한다.
- 먼저 여기서 소개하는 방법은 확률적으로 해성가능하다. 쉽게 likelihood, categorical prior, memory index의 posterior distribution을 계산 할 수 있다.
- incrementeal EM algorithm을 사용하는 likelihood를 maximizing함으로써 query의 대략적인 distribution을 학습한다.
- 이전의 논문에서 소개한 memory loss대신에 GAN loss로부터 최적화(optimize)가 이루어진다.
- slot histogram을 통해 각 sample들의 기여도의 정도를 결정한다.
The Discriminative output
우리가 구해야하는 p(y|x)를 구하기위해서 차근차근 하나씩 구해보도록 하자.
먼저 주어진 sample x에대해서, 우리는 먼저 discriminative probability를 계산하기위해서 어떤 memory slot들이 참조되어야하는지를 찾아낸다. Memory slot index를 나타내기위해서 c ∈ {1,2,...,N} 를 사용한다. 그리고 posterior distribution을 Von Mises-Fisher(vMF) mixture model 을 사용해서 memory indice에 대해서 나타내게 된다.
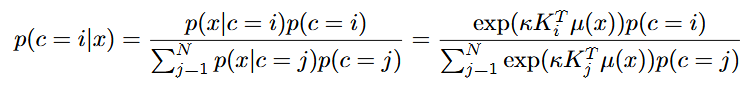
Bayes Rule을 이용해 sample x가 주어졌을때의 memory slot index의 확률을 구한다. 그것을 Von Mises Fisher를 이용해서 치환하게 된다. Memory index의 prior p(c)는 slot histogram을 normalizing하여 얻을 수 있다.
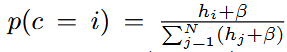
(β는 계산에서의 안정성을 위해서 사용되는 작은 상수이다. )
이제 p(y=1|c=i, x) = vi를 이용해서, discriminative probability p(y=1|x)를 측정할 수 있다. 이것은 c에대해서 결합확률(joint probability) p(y=1,c|x)를 marginalizing 함으로써 구하게 된다.

왼쪽의 좌변 p(y=1|x) 에서 우변으로 넘어갈 때에는 Law of total probability를 이용 한 것이다. 그리고 p(y = 1|c=i,x) = vi이므로 우측의 식이 된다.
하지만 이식을 계산하기위해서는 모든 sample x에대해서 size N인 memory에 대한 합을 구해야하기 때문에 계산하기 힘들다. 따라서 우리는 가장 큰 posterior probablity를 가진 top-k개의 slot S = {s1,s2,...,sk} 들만 뽑아서 근사하게 된다.

p(x|c)는 vMF likelihood 이고 p(c) 는 memory indice 에 대한 prior distribution이다.
이제 S를 구하게 된 우리는 discriminative output을 근사하게된다.

위의 식은 p(y=1|x)를 변형한 식에서,

를 변형하면 얻을 수 있다. p(c=i|x) 를 bayes rule를 이용해 바꾸어주고 범위를 S에대해서 바꾸어주면 쉽게 구할 수 있을 것이다.
따라서 이제 sample x가 주어졌을때 y(real or fake)의 확률을 근사할 수 있게 된다.
Memory Update
이 부분도 이전의 memory network와 상당히 비슷하지만 다른점이 있기에 다시 살펴보도록 하자.
먼저 기존의 memory 업데이트 매커니즘을 사용하고 거기다가 EM algorithm도 함께 사용한다. training sample 을 x라 하고 그것의 label을 y 라고 하는데 0(fake) 또는 1(real)의 값만을 가지게 된다.
다음으로 S(top - k 개의 slots들의 집합, 이전과 비슷하게 구하게 된다.)가 옳바른 label y를 포함하고 있냐 아니냐에 따라서 다른 업데이트 방식을 취하게 된다.
1. S에 옳바른 label이 존재하지 않을때에는 가장 오래된 메모리 슬롯을 a vector( age vector ) 를 이용해 찾고 x의 정보를 그것에 덮어씌운다. 그럼 가장 오래 된 메모리 슬롯의 index를 n이라고 하면 n 번째 K(key value)는 x가 inference net을 거친 qeury q가 되고 , v는 y가 되며 a는 0으로 초기화 된다. 또한 h는 N개의 memory slot들의 h(histogram)값들의 평균치가 된다.
2. S가 옳바른 label을 포함하고 있을때에는, memory key들이 새로운 sample x의 정보를 포함하도록 업데이트된다. 이것은 incremental EM algorithm을 T 번 거치게되면서 수정되게 된다.

expectation step과 maximization step 이 나와 있는데 뭘 하려는지는 느낌적으로 알겠는데 왜이렇게 하는지는 잘 모르겠다... 일단 참고하면 되겠다. 누군가 알고있다면 가르쳐 주세요..
The Memory conditional Generative Network
여기서 사용되는 MCGN은 InfoGAN의 generator에 기반을 둔다. 하지만 주요 차이점이 있다면, MCGN은 , random noize vector z뿐만이 아닌 conditional memory information도 함꼐 합성된다는 것이다. 즉 sample z뿐만아니라, MCGN은 real data에서 memory cell i의 정확한 출현빈도를 반영하는 확률로부터 memory index i를 뽑는다.

마지막으로 generator는 fake sample을 concat 된 [Ki,z]로부터 생성하게 된다.
다른 conditional GAN들과는 다르게, MCGN은 추가적인 주석이나 다른 어떠한 외부적인 encoder network가 필요하지 않다. 대신에 MCGN은 DMN이 학습한 conditional memory의 정보를 이용한다.

The Objective Function
이것 역시 InfoGAN의 mutual information 을 최대화하는 방식을 기반으로 사용했다. 하나 추가된 것이 있다면 Ki 와 G(z,Ki)사이의 mutual information loss term을 추가한 것이다.

최종적으로 memoryGAN의 objective는 다음과 같이 쓰인다.

How does MemoryGAN mitigate the two instability issues?
이 memoryGAN은 암묵적으로 z와 c가 독립이라는 가정하에 joint distribution p(x,z,c) = p(x|z,c)p(z)p(c) 를 학습하게 된다. 이러한 가정은 새로운 sample을 합성할때, 그것의 클래스나 군집의 모델링을 이미지의 특징, 스타일 등의 표현으로부터 분리시키는 것으로부터의 직관을 반영한 것이다. 이러한 분리는 구조적인 불연속 문제를 완화시켜준다. 데이터를 생성해낼때, 우리는 Ki 와 z 를 input으로써 뽑는다. Ki는 학습데이터의 중요한 클래스중의 하나를 표현한다. 그러므로 z는 클래스의 불연속에대해서 생각할 필요가 없고 단지 합성된 sample의 특징또는 스타일에 집중을 하게 되는것이다.
또한 직감적으로 memory module을 가지게 됨으로인해서 forgetting problem에도 덜 고통받는다. memory network 가 sample들의 클래스에대한 key vector 형태의 high-level representation을 기억하기 때문일지도 모른다.
Image generation performance

위의 4 줄은 성공적인 examples 이고 , 그 아래의 것들은 실패한 examples 이라고 한다.
Reference
[1] Memorization Precedes Generation : Learning Unsupervised GANs with Memory Networks



