
Deep Learning study
StarGAN : Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation 본문
StarGAN : Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
illinaire 2019. 4. 13. 18:41오늘 정리할 논문은 StarGAN이다. 인공지능수업에서 한 프로젝트에서 이 논문을 참고했었는데, 다시금 한 번 읽어보고 정리를 하려한다.
이 논문에서는 현존하는 접근방식들은 두가지이상의 도메인을 다루는데 있어서 제한된 scalability 와 robustness가 있다고한다. 이유인 즉슨, 모든 domain에 대해서 독립적인 모델들이 만들어져야했기 때문이다.
그래서 제안한 것이 StarGAN구조이다.
- 단 하나의 모델을 가지고 여러가지의 domain들에대해 image-to-image translation을 다루는 것을 수행한다.
- 동시에 다른 domain을 가진 dataset들을 동시에 학습시킬수있다. (mask vector method)

위의 사진들은 Celeb A 의 데이터셋을 Multi-domain image-to-image translation한 결과이다. 모든 input은 Celeb A dataset 이지만 우측의 input에 적용 된 attribute는 Celeb A 가 아닌 RaFD dataset 으로부터 학습 된 것이다. 즉, single generator network로 여러개의 domain을 가진 dataset을 학습한 것을 보여준다. 또한 한 domain의 dataset에서 학습 된 attribute를 다른 data set에 적용 시킬 수 있는것을 보여준다.
그럼 본격적으로 StarGAN에대해 알아보기전에 논문에서 자주 나오는 용어 몇가지를 알아보자.
attribute : 여기서는 이미지에 내재된 의미있는 feature(특징)이라고 설명한다. 예를들면 hair color, gender or age 등등..
attribute value : attribute의 특정한 값이다. 예를들면 hair color의 attribute value는 balck/blond/brown 이고, gender의 attribute value는 male/female이 된다.
domain : 같은 attribute value를 가지는 이미지 셋 이다. 예를들면 gender 가 female 인 이미지들은 하나의 domain이 된다.
이정도알고 본론으로 들어가도록 하자 !
Introduction
이것 이전에 존재하는 모델들은 multi-domain image translation tasks에서 비효율적이고 비효과적이였다. 왜냐하면 k개의 도메인들 사이의 모든 mapping을 배우기위해서는 k(k-1)개의 generator가 만들어져야하기 때문이다.

위의 그림이 잘 설명해 주고있다. 4개의 domain간의 mapping을 모두 학습하려면 4*3개의 generator가 필요한 것을 볼 수있다. 그러나 StarGAN은 오로지 하나의 generator로만 모든 매핑들을 학습시킬 수 있다는것을 알 수 있다.
여기서 제시한 아이디어는 고정된 translation(예를들면 black to blond hair만을 학습)을 배우는것이아니라, 모델이 image와 domain정보를 함께 input으로 받아서 input image를 대응되는 domain으로 translate를 할 수 있도록 학습시키는 것이다. 이 과정에서 label을 사용하는 그것은 domain정보를 담고있는 label이다. label은 binary 또는 one-hot vector로 이루어져있다.
학습과정에서는 target domain label을 만들어 모델이 target domain으로 이미지를 변화시키도록 학습한다.
그 외에도 domain label에 mask vector를 추가해 줌으로써 다른 dataset의 domain사이의 결합된 학습이 가능하다.
Star Generative Adversarial Networks
Multi-Domain Image-to-image Translation
이 논문의 목적인 single generator G로 다수의 domain들사이의 mapping을 학습하게 하려면, G는 어떤 target domain label c를 이용해서 input image x 를 output image y로 변환하는것을 배워야 한다. 즉, G(x,c) → y.
또한 discriminator D는 source(real로부터의 image인지 G가 생성해낸 image인지)와 domain labels에대한 확률분포를 만들어 내야한다. 즉, D : x → {Dsrc(x), Dcls(x)}.

위의 그림을 보면 여느 GAN모델과 같이 2개의 모듈로 구성되어 있다. discriminator인 D 와 generator인 G로 구성된다.
a) D는 real image 와 fake image를 구별하는 것과 동시에 real image일때 그것과 상응하는 domain을 분류해내는 것을 학습힌다.
b) G는 input으로 image와 동시에 target domain label을 받고 fake image를 생성한다.
c) G는 original doamin label을 가지고 fake image를 다시 original image로 reconstruction하려고 한다.
d) G는 real image와 구분불가능하고 D에의해 target domain이 분류가능한 이미지를 생성하려 한다. (즉 real image처럼 보이려고 노력하는 것이다.)
adversarial Loss
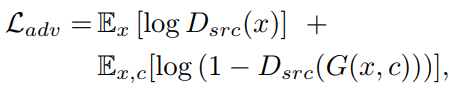
G는 x와 target domain label을 가지고 G(x,c)라는 이미지를 만들어내고, D는 real and fake image들을 구분하려고 노력한다는 의미의 loss이다.
log함수를 안다면 쉽게 이해가능할 것이다. (src(source)로 real data에서 온것이냐 아니면 생선된 fake data에서 온것이냐를 말한다. ) D는 real로 판별이 된다면 1에 가깝게 출력을 낼 것이고, fake로 판별이 된다면 0에 가깝게 출력을 낼 것이다.(D는 확률값을 가지기 때문이다.) 그렇다면 Loss는 줄어드는것이 좋은 것이기때문에 real image 인 x 에대해서 Dsrc(x)는 1을 가지도록 학습하고, Dsrc(G(x,c))에서는 G가 real인 것처럼 학습을해야하니 역시 1을 가지도록 학습을 한다면 Loss가 최소가 될 것이다. (log함수는 정의역이 1일때 0, 0일때 -∞로 발산한다)
위의 식은 GAN을 조금만 안다면 쉽게 이해 할 것이다.
Domain Classification Loss
주어진 input image x 와 target domain label c에대해서, x가 ouput image y로 변환되었을때, 그것이 target doamin c로 분류되는 것이 목적이다. 그러기위해서 D와 G를 optimize할때 domain classification loss 를 첨가한다.
이것은 두개의 term으로 나뉘게 된다.
1) domain classification loss of real images used to optimize D
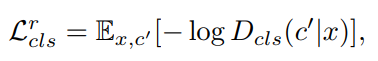
Dcls(c'|x)는 real image x가 주어졌을때 D 가 계산해낸 domain label c'일 확률분포이다. 위의 식은 adversarial loss와 같으니 설명은 생략한다. 결국엔 이 Loss를 최소화함으로써, D는 real image x 를 그것에 대응되는 original domain c'으로 분류시키는것을 배운다.
2) domain classification loss of fake image used to optimize G

다시 말해서, G는 target domain c로 분류되어질 수 있는 이미지를 생성하도록 이 Loss를 최소화 하려고 하게된다.
Reconstruction Loss
여기서 한 가지 Loss를 더 추가하게된다. 왜냐하면 위에서 소개한 Loss 들 만으로는 input image의 target domain에 관련된 부분만을 변화시킬때 input image의 본래 형태를 잘 보존 할 수 없기 때문이다. 그래서 Generator에 한 가지 loss를 더 적용하게 된다.
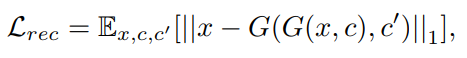
G는 변환된 image G(x,c)와 original doamin label c'을 input으로 받고 original image x 를 복원하려 하게되는 것이다. L1 norm으로 계산을 하게된다.
Full Objective
이렇게 해서 최종적으로 G와 D에대한 objective fucntion 이 나오게 된다.
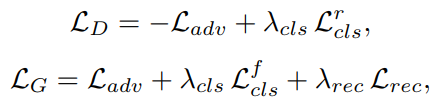
λcls와 λrec는 hyperparameter로, domain 분류와 reconstruction loss들 의 상대적인 중요도를 컨트롤한다.
Training with Multiplel Datasets
StarGAN의 중요한 이점은, 다른 domain을 가진 datasets들을 동시에 포함하는 것 이다. 그러나 다수의 dataset들을 학습시킬때의 문제는 label 정보가 각 dataset에 부분적으로만 있다는 것이다.
예를들어 Celeb A와 RaFD의 경우에, Celeb A는 hair color 와 gender에대한 attribute만을 가지고 facial expression 을 나타내는 happy 와 angry같은 attribute는 가지지 않는다는 것이다. 역으로 RaFD도 마찬가지다. 이것이 왜 문제가 되나면 , 변환된 image G(x,c)르보터 input image x를 reconstruction하려면 label vector c'에 완전한 정보가 있어야하기 때문이다.
Mask Vector
이러한 문제를 해결하기 위해서 mask vector m을 소개한다. 이것은 StarGAN이 명시되지 않은 label에 대해서는 무시하게하고 명시된 label에대해서는 집중하게 해준다. 여기서 n차원의 one-hot vector를 사용한다. (n은 dataset의 수 이다)

ci는 i번째의 dataset의 label들의 vector를 나타낸다. 또한 ci는 binary attribute를 가진 binary vector 또는 categorical attribute를 가진 one-hot vector이다.
여기서 dataset은 Celeb A와 RaFD이므로 n은 2가 된다.
즉, mask vector 에 어떤 dataset 인지를 명시해 줌으로써 , 해당 dataset의 attribute에 관련된 label에 집중을 한다는 것 이다. 예를들면 CelebA를 학습시키려고 명시해 주었다면 RaFD에 관련된 facial expression 들은 무시하고 학습한다는 것이다.
CelebA와 RaFD를 교차시킴으로써 Discriminator는 두 dataset에서 차이를 구분짓는 모든 feature들을 학습하게 되고, Generator는 모든 label을 컨트롤하는것을 학습하게 된다.
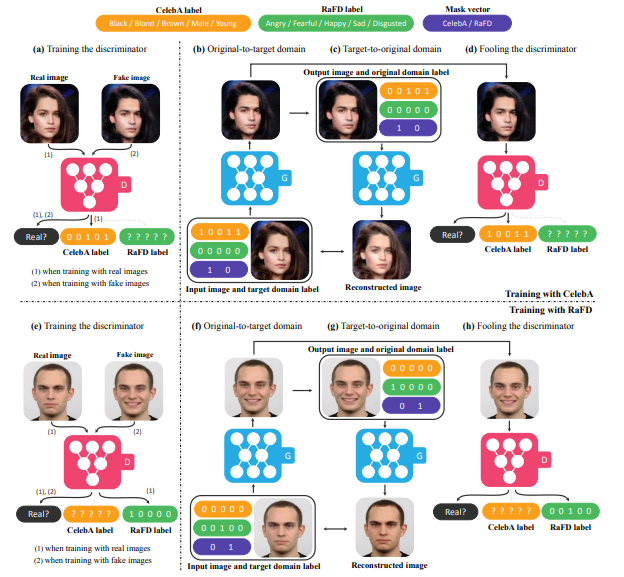
StarGAN이 CelebAdhk RaFD dataset을가지고 학습할때의 모습을 보여주는 그림이다.
말했듯이 CelebA같은 binary attribute(black,blond,brown,male,young)에 대한 label은 binary vector로 표현 되었고, 반대로 RaFD같은 categorical attribute(Angry, Fearfule, Happy, Sad, and Disgusted)에 대한 label은 one-hot vector로 표현되어 있다. mask vector는 2차원 one-hot벡터로 CelebA와 RaFD중 valid 한 것을 가리킨다.
혹시 제가 잘못됐거나 잘못 이해한 부분이 있다면 알려주세요 ~
Reference
[1] StarGAN : Unified Generative Adversarial Networks for Multi-Domain Image-toImage Translation


