
Deep Learning study
Learning To Remember Rare Events 본문
오늘은 memory network에 관한 논문을 정리해 보려한다.
neural network는 매우 좋은 성능을 가져오지만, 학습기키기가 까다롭다는 점이있다. 그에대한 예시로, 학습할때 필요한 방대한 양의 dataset과 학습을 한 data에 대한 것을 잘 잊어버리는 것 이다.
그래서 논문에서 다양한 neural network에 사용 될 life-long memory module을 소개한다. 이러한 memory 구조를 가지게 됨 으로써 기억능력에대한 향상, 그리고 one-shot learning(각 class별로 하나 또는 적은 training sample로 부터 학습을 하는 것)이 가능하다고 말한다.
introduction
여기서 중점적으로 소개할 내용은 다양한 neural network들에서 one-shot learning을 가능하게하는 memory module에대한 소개이다. 이 memory module은 key와 value 의 pair로 구성되어져있다.
Key 는 network의 한 layer의 output 값(activation 값)이며 value는 주어진 sample의 ground-truth target 이다.
이렇게 저장된 pair들로 비슷한 activation값을 가진 data에대한 정보를 얻게되며, 단 한 번이라도 training sample에 존재 했다면 그 activation값이 memory에 저장되기 때문에 one-shot learning에도 유용하게 사용가능하다.
Memory Module
그럼이제 memory의 구조가 어떤지 살펴보자. 위에서 말했듯이 key 와 value의 pair로써 존재한다. 하지만 실제 메모리는 triple 로 세가지의 정보를 가지고 있다.
- K : memory key들의 matrix이다. 다시말해서 key vector들의 저장공간 인것이다. 이 곳에 저장되는 key들은 모두 normalized 되어져 있다. 즉, ||key|| = 1. memory-size 만큼의 row와 key-size만큼의 column으로 구성되어있다.
- V : momory value들의 vector이다. K의 key vector와 대응되는 value값들이 저장되어있는 공간이다. 예를들어, classification에서의 value는 class에 대한 label( class의 번호 ) 이 담겨있을 것 이다. memory-size만큼의 크기를 가진 vector로 구성되어있다.
- A : 추가적으로 생긴 vector이다. 이 곳에는 memory에 들어온 key-value의 pair의 age 가 담겨져있다. memory크기가 무한정 일순 없으므로, memory 갱신을 위한 값이라고 생각하면된다.
이렇게 3가지의 triple로 M = (K, V, A)로 구성된다.

memory query( q )는 key-size의 크기를 가진 vector이며 , 이것 역시 normalized 되어있다. 즉, ||q|| = 1.
Query로 q가 주어졌을때 memory(M)에서 nearest neighbor(의미 그대로 q랑 가장 비슷한 key값을 찾겠다는 말 이다.)를 정의한다.

여기서는 nearest neighbor를 query q 와 내적값이 최대가 되게하는 key 로 정의했다. 또한 모든 key들은 normalized되어있기때문에 이것은 cosine similarity(정보검색 수업시간에 열심히 했던건데 반갑네... )와 대응된다고 볼 수 있다.
여튼 이제 이것을 최종적으로 k nearest neighbors로 확장시킨다.

Query q에대한 memory M에서의 k nearesty neighbors들을 나타내는 notion이며, n1부터 nk까지 내림차순 정렬되어있다. 즉, cosine similarity가 가장 큰 key의 index가 n1이 된다. 그리고 이 값을 main result로써, 이것의 value값을 V[n1]이라 한다.
Memory Loss
query q가 주어졌을때, 우리가 옳바른 값 value v의 값을 얻었다고 생각해보자. Classification의 경우에 위에서 말 했듯이 v는 class label이 될 것이고, sequence to sequence에서는 v가 현재 step 에서 요구되는 token의 값 일것이다.
위의 k nearest neighbors (n1, ... , nk)에서, p 를 V[np] = v를 만족시키는 가장 작은 index라 하고, b를 V[nb] ≠ v 를 만족하는 가장 작은 index라 하자. 그리고 np를 positive neighbor , nb를 negative neighbor이라고 부르자.
만약 찾아낸 k 개의 nearest neighbor중에 positive neighbor이 없다면, memory에서 value v를 가진 임의의 vector를 가져오기로 하자.
이제 memory loss를 다음과 같이 정의한다.

위에서 말 했듯이 오른쪽의 term들은 cosine similarity를 나타낸다. 즉, negative neighbor과 q 의 cosine similarity에서 positive neighbor과 q의 cosine similarity를 뺀 값을 최적화 하는 것이다.
이게 무슨 말 인가생각해보면 positive와의 similarity는 최대(~1)가 되어야하고, negative와의 similarity는 최소(~0)이 되어야 한다는 것 이다. (v가 나온 key 와는 관련이 높으면 좋겠고, v가 나오지 않은 key 와는 관련이 적도록 하고싶다는 것이다.)
Memory Update
Loss를 계산하는것에 이어서, v에 대응되는 새로운 query q가 주어졌을때에 memory M을 업데이트 시켜줄 것이다.
Memory 업데이트는 main value가 이미 옳바른 value v를 가지느냐 아니냐에 따라서 다르게 진행된다.
먼저 위에서 처럼 n1 = NN(q,M) 을 q에대한 the nearest neighbor이라고 하자.
1. memory가 옳바른 value를 return 했을때. 즉, V[n1] = v.
이 때에는 현재 n1에 해당하는 key와 q의 평균치를 계산하고 normalize를 해 준다. 그리고 그 age값 A[n1]은 0으로 업 데이트 해 준다.

2. memory가 옳바르지 않은 value를 return 했을때. 즉, V[n1] ≠ v.
이 때에는 memory에서 새로은 저장공간을 찾아서 (q,v) pair를 입력시킨다. 새로운 저장공간은 가장 오래된 item들을 찾아서 (A의 값을 이용 ) 그것들중에 랜덤으로 선택하여 쓰게된다. 좀 더 formal하게는 아래의 식을 이용하여 찾게 된다.
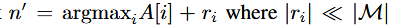
그리고나서 K[n'], V[n'], A[n'] 값을 갱신 시켜준다.

전체적인 memory 업데이트 과정은 아래 그림에 묘사되어있다.

Convolutional Network with Memory
간단하게 memory module이 어떻게 쓰이는지 알아보고 마치도록 하자.
논문에서 소개한 CNN에 대한 설명이다. 여기서는 간단하게 convolutional layer들과 마지막 Fully Connected layer들로 구성되어져있다. 보통의 classification을 수행하는 conv net이라면 마지막에는 classifier로 softmax같은 layer가 있겠지만 여기서는 그 대신에 memory module을 사용하게된다. 즉 마지막 FC layer의 output 을 query 로 사용하게 되는 것이다.
즉, key값들(또는 query q)은 neural net을 거쳐서 나온 vector로 input이 feature extractor를 거쳐서 나온 encoding 된 vector라고 보면 앞의 내용들을 이해하는데 도움이 될 것이다.
Reference



